

SEO is challenging. In today's competitive world, it is really hard for content marketers to rank for anything but laser-focused keywords.
These so-called long-tail keywords are more specific (and usually longer) search terms visitors use when they are closer to a purchase, want to find information about something specific, or are using voice search.
They have less search traffic but higher conversion value. They also have lower competition than generic terms (a.k.a. head terms), so ranking for them is much easier and cost-efficient. Moz has a great article illustrating the concept.
Take "web scraping" and "web scraping software for lead generation", for example. The former is used to find out basic information about web scraping. In the case of the latter, on the other hand, the user is searching for tools tailored to lead generation so she'll likely try out some of the top results.
As I was researching ways to find long-tail keywords, this excellent post caught my attention. It offers 9 techniques to discover them.
In this article, we'll leverage one of them, and that would be Related Searches that Google offers on their SERPs (Search Engine Results Pages).
What you’ll build
In this guide, we’ll use Node.js and Puppeteer to build a web scraper that takes a search term as input and generates a list of long-tail keywords related to it. To do that, it:
- Takes an initial term and performs a Google search for it
- Extracts the keywords from the related searches section on the bottom of the SERP, writes them in a text file
- Performs a search for all of those related terms
- Extracts the related searches for those, appends them to the file
- And so on...until there are no more suggestions or we reach the page limit
We’ll also make sure we store (and search for) each keyword only once.
You can find the full source of the project on GitHub. Feel free to review it if you get stuck.
Ready? Let’s jump right in!
Project setup
First, make sure Node.js and npm are installed by running the following commands to check their versions:
node -v
npm -v
If they aren’t, start from here: https://docs.npmjs.com/downloading-and-installing-node-js-and-npm
Next, let’s set up the project by creating a directory and initializing the npm package:
mkdir keyword-scraper
cd keyword-scraper
npm init -y
The -y flag tells npm to skip the questionnaire and just use the default values. This will create a package.json file that holds the basic configuration for your project like its name, version, dependencies, scripts, and much more.
Installing dependencies
We need to install Puppeteer to do the actual scraping and Yargs for parsing command-line arguments:
npm i puppeteer yargs
Puppeteer is a node library that allows controlling headless Chrome or Chromium via a high-level API. That means performing basically any type of action a real user could do. It's an excellent choice when the page we need to scrape is highly dynamic, i.e. we need to get past some popups or part of the data is fetched asynchronously using Javascript.
Note, however, that for static pages, HTML parsers like Cheerio are preferred because they are much faster.
Yargs is very handy for parsing command-line arguments. Node exposes them in process.argv, but it is a raw string array that also holds some extra stuff we don't need (the node executable's path, and the script currently being run). Also, the arguments, given as key-value pairs separated by '=' are not parsed. Yargs will help us out here.
Building it out
Now we can start building our scraper. We’ll implement everything in a single file named scraper.js to keep things simple. Create it in the project’s directory and add the following lines to import the modules we need:
const puppeteer = require('puppeteer')
const https = require('https')
const fs = require('fs')
const yargs = require('yargs/yargs')
const {hideBin} = require('yargs/helpers')
Tip: You might want to use a code editor for faster development. Visual Studio Code is an excellent editor and it’s free.
Open package.json and change any occurrence of index.js to scraper.js, since that’s our main source file. You can also remove the "scripts" property, as we won't be doing unit testing in this guide.
Handling command-line arguments
In order for our tool to be flexible, we’ll accept the following command-line arguments (each mandatory):
- keyword - the initial keyword we’ll search for
- limit - the maximum number of pages to scrape
- file - the path to the output text file in which we’ll store the results
Add the following code to handle them:
const argv = yargs(hideBin(process.argv)).argv
const initialQuery = argv.keyword
const outputFile = argv.file
const maxPages = argv.limit
if (!initialQuery || !maxPages || !outputFile) {
return console.log('USAGE: node scraper.js --keyword=<keyword> --limit <page_limit> --file=<output_file>')
}
If one or more of them are missing, we'll display the usage of the tool and exit. For now, I haven't implemented any other validation to keep things simple.
Getting the relevant CSS selectors
Let’s study our subject page a little bit. Open Chrome in incognito mode and perform a Google search with your keyword of choice (e.g. "web scraping"). Incognito mode avoids personalized search results, potentially resulting in a slightly different page layout.
The first time you open Google, you’ll most likely run into the Cookie Consent Popup. This will be a slight challenge for us, but we’ll handle it later. For now, we need to find the CSS selector of the “I agree” button.
Open up Chrome Developer Tools and inspect the button’s element:
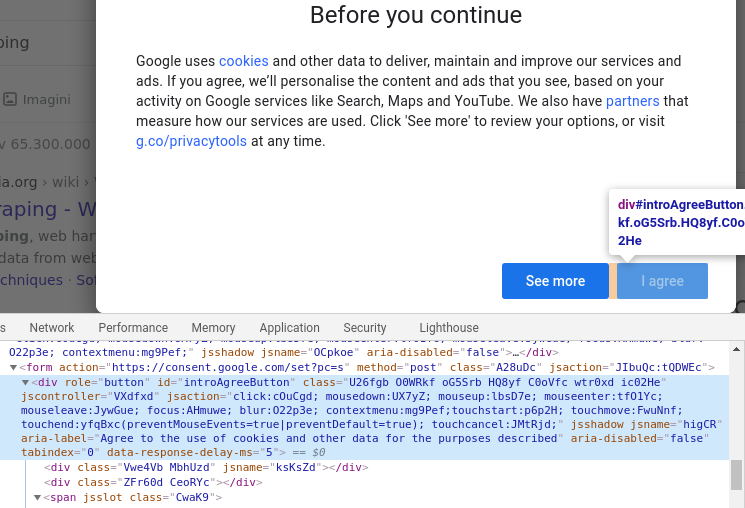
As we see, the button is actually a div with "introAgreeButton" as its ID. So let’s grab this ID and save it as a constant:
const cookiePopupButton = '#introAgreeButton'
Now click that agree button to accept the policy and display our actual search page. After performing the search, if you scroll down to the bottom, you’ll see some related searches suggested by Google. We need to grab the common selector for these terms. Open up Dev Tools again and inspect one of them:
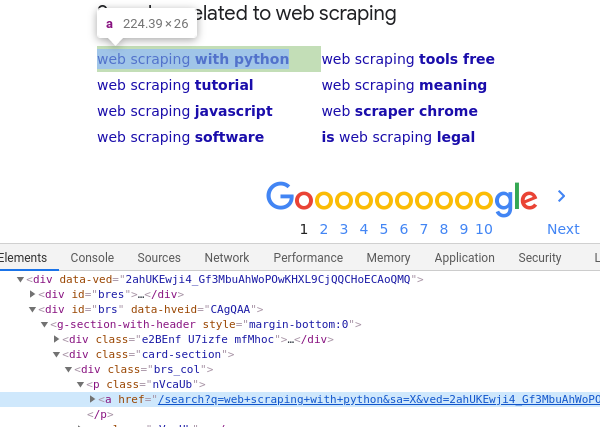
Again, define its selector as a constant:
const keywordSelector = '.card-section .nVcaUb > a'
A few helper methods
We'll write two helper functions. The first one takes a search term as string and returns the correct Google URL that searches for that term:
const getSearchURL = (query) => `https://google.com/search?q=${encodeURIComponent(query)}&lr=lang_en`
Note that we are using encodeURIComponent to make sure the search terms are correctly encoded in the URL ("web scraping" will become "web%20scraping").
The second function one takes a Puppeteer page object and it extracts the text values of the recommended keywords based on the selector we figured out above:
const extractRelatedSearches = async (page) => {
try {
return await page.$$eval(keywordSelector, arr => arr.map(e => e.textContent.toLowerCase()))
} catch (e) {
console.log('Error extracting keywords.', e)
}
return []
}
Getting past the cookie consent popup
We need to get past the cookie consent popup. Our keyword recommendations won't be loaded until then. To do that, we'll tell Puppeteer to wait until the popup's iframe loads, then locate the "I agree" button and click it. Implement the following function:
const acceptCookiePopup = async (page) => {
try {
await page.waitForSelector("iframe", {timeout: 2000})
const frameHandle = await page.$('iframe')
const frame = await frameHandle.contentFrame()
await frame.waitForSelector(cookiePopupButton, {timeout: 2000})
await frame.click(cookiePopupButton)
} catch(e) {
console.log('Cookie consent button not shown.')
}
}
The scraper's logic
Finally, let's put everything together and implement our scraper.
const httpsAgent = new https.Agent({ keepAlive: true });
(async () => {
// Initialize Puppeteer and open a new page
const browser = await puppeteer.launch({httpsAgent})
const page = await browser.newPage()
let pagesScraped = 0
let query
// We'll store the unique search terms in a Set
const uniqueTerms = new Set()
uniqueTerms.add(initialQuery)
const requestQueue = []
// Open our output file in append mode
const stream = fs.createWriteStream(outputFile, {flags: 'a'})
try {
// Load the initial search page
await page.goto(getSearchURL(initialQuery), { waitUntil: 'networkidle2' })
// The cookie consent dialog will most probably pop up at the first search. So we'll find the accept button and click it.
await acceptCookiePopup(page)
do {
// Extract the related search terms from the bottom of the page. Convert them to lower-case so we can detect duplicates more easily.
const newTerms = await extractRelatedSearches(page)
// For each new search extracted ...
newTerms.filter(term => !uniqueTerms.has(term)).forEach(term => {
uniqueTerms.add(term)
// Write it in the output file
stream.write(term + '\n')
// Add it the to the request queue
requestQueue.push(term)
})
pagesScraped++
// Dequeue the next term
query = requestQueue.shift()
if (query) {
console.log(`Performing search for '${query}'...`)
await page.goto(getSearchURL(query), { waitUntil: 'networkidle2' })
}
} while (query && pagesScraped < maxPages)
} catch (e) {
console.log('Error occurred when scraping page. ', e)
}
// Clean up things
stream.close()
await browser.close()
})();
First, we create a custom https agent and tell it to reuse existing connections by setting keepAlive to true. This will improve performance.
Our scraping logic is then wrapped in an anonymous async method, which is then called inline at the end.
We initialize Puppeteer (passing in our custom agent) and create a new page.
We then use a Set to store unique terms as that is more efficient for ensuring there are no duplicates than an array. We also use an array as a queue (via its push and shift methods) to enqueue and dequeue new requests.
Next, we open the output file in append mode since we'll write newly found terms after each scraped page.
We load up the search page of the initial keyword, then call acceptCookiePopup to get past the cookie consent popup.
We then open a do...while loop which will run until there are no more new requests in the queue (new keywords to search for) or we reached our page limit. In the loop, we call our helper method to extract related keywords from the current page, filter out duplicates, then add them to the set and request queue and also append them to our file. We increment our page counter and dequeue the next keyword to search for.
Finally, after the loop, we close the file and the browser object and we're done.
Let's run it!
To run it, invoke the script via node and set its arguments. For example:
node scraper.js --keyword="web scraping" --limit=30 --file="results.txt"
Conclusion
So there you have it. :)
We saw that it's not too hard to put together a basic scraper that actually does something useful. Now with a sizable list of keyword alternatives, you'll have a much better idea about what are people generally searching for, and what to write about in your next blog post.
Puppeteer is a powerful library and a great choice when we need to scrape dynamic pages. For static pages, however, HTML parsers such as Cheerio are preferred as they are much faster. There are also out-of-the-box solutions that handle all this without needing you to code it.
Again, check out the full source if you get stuck.
I'd be curious about your experience with Puppeteer or other libraries/technologies. I know a lot of people use Python for scraping. So share your views (or ask questions) in the comments.
Cheers!